Delta Lake essential Fundamentals: Part 4 - Practical Scenarios
Multi-part series that will take you from beginner to expert in Delta Lake
🎉 Welcome to the 4th part of Delta Lake essential fundamentals: the practical scenarios! 🎉
There are many great features that you can leverage in delta lake, from the ACID transaction, Schema Enforcement, Time Traveling, Exactly One semantic, and more.
Let’s discuss two common data pipelines patterns and solutions:
Spark Structured Streaming ETL with DeltaLake that serves multiple Users
Spark Structured Streaming- Apache Spark structured steaming are essentially unbounded tables of information. There is a continuous stream of data ingested into the system. As developers, we write the code to process the data continuously. ETL stands for Extract, Transform and Load.
Scenario - Ingest data from Kafka topic, process the information using Spark structured streaming, and save it to DeltaLake for multiple users on-the-fly queries.
Note! The output of the solution/pipeline is used by real users and not a machine, which means that there is no need to refresh the data every couple of seconds as the person taking actions on the data won’t be able to use it.
System Requirements
Let’s assume we have these system requirements:
Input: any unstructured one input stream for example Kafka topic
Output: structured tabular data for users to query
Latency: 5 minutes
Constraints: multiple users query the table at the same time
High-level Pipeline Architecture

Advantages
In our scenario, we have multiple users that query the data on the fly and should see the same data - single source of truth. In distributed steaming, when we query the data, it might be that from two identical queries that ran at the same time, we will get different results. This is why we introduce DeltaLake into the pipeline. We save the streaming tabular data in DeltaLake, which in practice means that the user read operations take place on the DeltaTable snapshot, which guarantees consistency of the data. At the same time, the table is continuously being written.
Simultaneously, the user can also run updates/deletes and fixes on the data when necessary, this is important for controlling incoming data that are bounded to GDPR or other compliances. The conflicts are resolved using Delta conflict resolution mechanism (Discussed in Part 2 - the DeltaLog).
If you are using Databricks services, you will get the Auto Optimize out of the box, which coalesces small files into larger files using Auto Compaction.
When to exclude Delta Lake
As much as it’s important to know what are the advantages and when to use DeltaLake, it’s important to understand when to exclude it. For example, when you want to have a latency of seconds to update a Key-Value output for lookup tables, you should probably avoid DeltaLake since it introduce the overhead of the optimistic concurrency and commits to the DeltaLog itself. But if your system can handle a couple minutes of latency, you should consider using it for enforcing data - single source of truth for your users.
What to use instead of DeltaLake for updating lookup tables with seconds latency
A lookup table is an array that replaces runtime computation with a simpler array indexing operation, which means that the data is being stored in memory. This makes read queries significantly faster than loading data from disk, which involves I/O operations. Hence for stateful streaming operations, we would prefer to use in-memory databases such as Redis, Cassandra or Amazon DynamoDB. This solution is more expensive since it requires dedicated servers/services to be used in the system, vs. using DeltaLake which is a storage layer, but this is the price to be paid for lookup table that is being updated and accurate to all users with a latency of seconds.
Join Multiple Data Streams based on a common key on Azure Databricks
Scenario - Ingesting data into the system from multiple different data streams that need to be joined based on a common key written to a shared table for future analytics/ML workloads/lookup tables.
System Requirements
Let’s assume we have these system requirements:
Input: multiple unstructured input streams from various sources
Output: tabular data combining the streams inputs
Latency: 2 minutes
Constraints: support join on one fast and one slow data streams with dimension changes
Slowly changing dimensions is a data management problem where the data warehouse contains relatively static data and schema linked to a dimension table that can change its schema and data as time passes. To learn more about it, read here. Imagine a user bank account information that needs to be joined by a user bank transaction.
Suppose you are familiar with broadcast join mechanism. In that case, the solution might look simple, broadcast the small static data table and use Spark Structured Streaming to stream the fast, ever-changing stream for the join operation.
But, what if you are attempting to join two big tables that constantly change? This is when you need to understand how to leverage Delta Lake versioning capabilities.
High-level Pipeline Architecture
In this high-level architecture diagram, we have 2 Spark workloads; the first one is a batch, reading data from MongoDB, processing it, and saving it to DetlaLake. The second one is the fast data, ingesting data from a Kafka topic directly into Spark Streaming and joining the fast data with the slow data saved in DeltaLake. After the join and further logic, the data is being kept in a tabular store for future use.
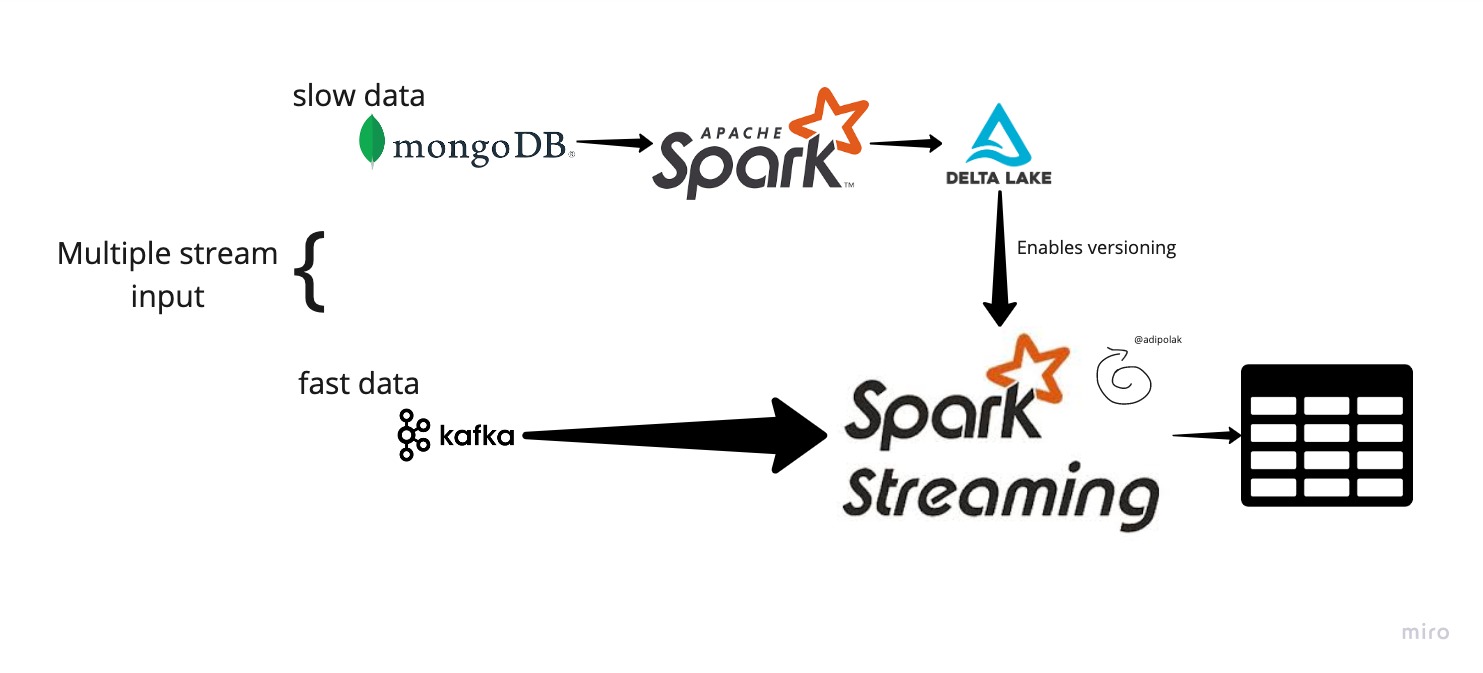
Advantages
Without DetlaTable, Structured streaming will hold a static view of the first “slow” data, and it won’t be updated until you restart the streaming query. But we already know that this data can be updated; think about the bank customer who changed their home address, and it needs to be updated in the system. Using DeltaLake helps introduce table versioning and allows you to control the changes and read/use the latest/most updated version inside the streaming query without restarting it.
Note: the DetlaLake automatic reload without restart capabilities are currently supported in Databricks environment but not yet in the OSS.
I hope you enjoyed reading about Delta Lake, the two practical scenarios, and the breakdown of the open-source;
I will continue to share scenarios, insights, and code samples throughout the blog. As always, if you have questions, suggestions, ideas, please don’t hesitate to DM me on Adi Polak 🐦.
If you would like to get monthly updates, consider subscribing.
💡 Learn more!
- Watch this video on how to architect structured streaming.
- Read here about Azure Databricks and Streaming.
If you didn’t get a chance to read the previous posts, read here:
- Delta Lake essential Fundamentals: Part 1 - ACID
- Delta Lake essential Fundamentals: Part 2 - The DeltaLog
- Delta Lake essential Fundamentals: Part 3 - Compaction and Checkpoint
- Delta Lake essential Fundamentals: Part 4 - Practical Scenarios (You are here)