Apache Spark Ecosystem, Jan 2021 Highlights
Adi Polak
If you’ve been reading here for a while, you know that I’m a big fan of Apache Spark and have been using it for more than 8 years.
Apache Spark is continually growing. It started as part of the Hadoop family,
but with the slow death of hadoop and the fast growth of Kubernetes, many new tools, connectors and open source have emerged.
Let’s take a look at three exciting open sources:
Ray:
Ray is an open source, python based framework for building distributed applications.
Their main audience is ML developers and Data Scientists who would like to accelerate their machine learning workloads using distributed computing.
Ray was open sourced by UC Berkly RISELab, the same lab who created the AMPLab project, where Apache Spark was created.
BTW, if you are curious, their next big 5 years project is all about Real-time Intelligence with Secure Explainable decision.
RayOnSpark is a feature that was recently added to Analytic Zoo, end to end data analytics + AI open sourced platform, that helps you unified multiple analytics workload like recommendation, time series, computer vision, nlp and more into one platform running on Spark, Yarn or K8S.
“RayOnSpark allows users to directly run Ray programs on Apache Hadoop*/YARN, so that users can easily try various emerging AI applications on their existing Big Data clusters in a distributed fashion. Instead of running big data applications and AI applications on two separate systems, which often introduces expensive data transfer and long end-to-end learning latency, RayOnSpark allows Ray applications to seamlessly integrate into Apache Spark* data processing pipeline and directly run on in-memory Spark RDDs or DataFrames.” Jason Dai.

To learn more about Ray and RayOnSpark, checkout Jason Dai article from RISELab publication.
Koalas:
Koalas is Pandas scalable Sibling:
From the Pandas docs: “pandas is an open source, BSD-licensed library providing high-performance, easy-to-use data structures and data analysis tools for the Python programming language.”
From the Koalas docs: “The Koalas project makes data scientists more productive when interacting with big data, by implementing the pandas DataFrame API on top of Apache Spark.”
If you are familiar with exploring and running analytics on data with panads,
Koalas provides a similar API for running the same analytics on Apache Spark DataFrames.
Which makes it easier for Pandas user to run their workloads at scale.
When using it, notice the different versions of Koalas, many new versions are NOT available with Spark 2.4 and require Spark 3.0 cluster.
Koalas is built with an internal frame to hold indexes and information on top of Spark DataFrame.
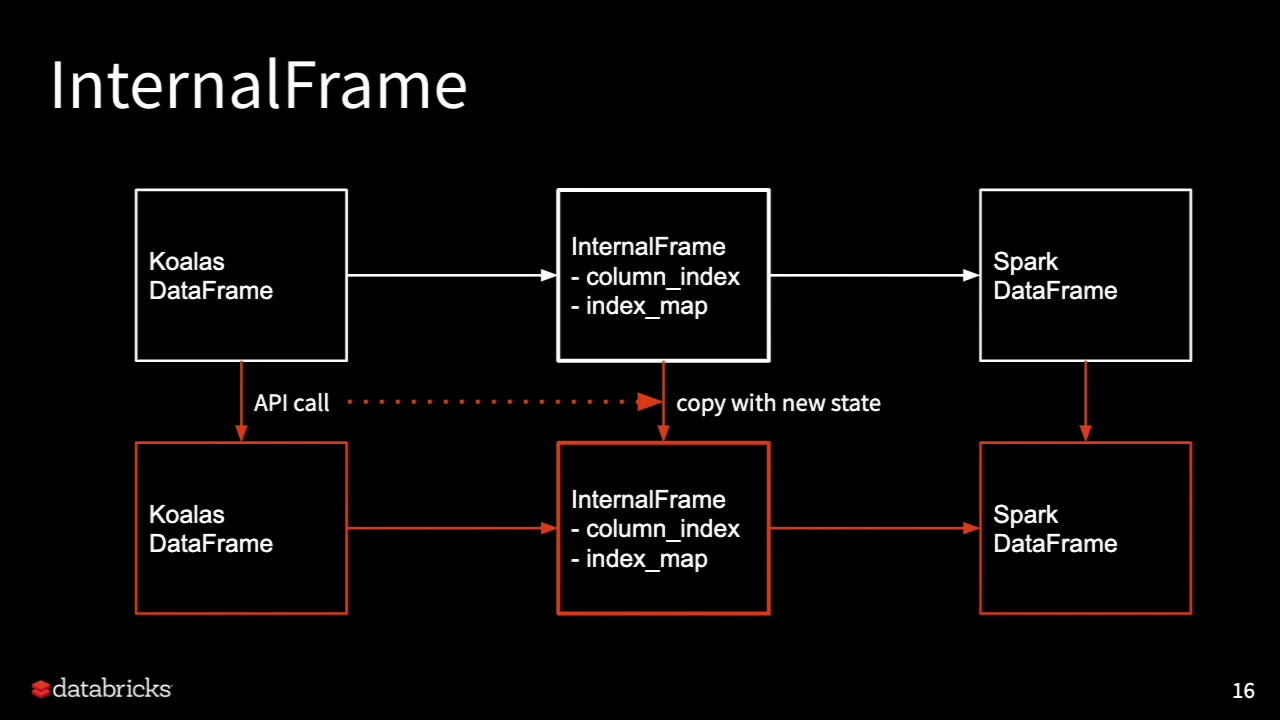
To learn more about it, checkout Tim Hunter talk on Koalas from Spark Summit 2019.
Delta Lake:
Delta Lake is nothing new with the Spark ecosystem, but still many confuse Delta Lake to be a … DataBase! (DB) well.. delta lake is NOT a database.
Detla Lake is an open source storage layer that brings ACID (atomicity, consistency,
isolation, and durability) transactions to Apache Spark and Big data workloads but is not a DB! Just like Azure Blog storage and AWS S3 are not acting as databases, they are defined as storage.
Delta helps with ACID that is hard to achieve and a great pain point with distributed storage.
It provides scalable metadata handling on the data itself.
When combined with Spark this is highly useful due to the nature of Spark SQL engine
the catalyst which uses this metadata to better plan and executed big data queries.
There is also data versioning through snapshot of the storage named Time Travel feature. I recommend being mindful with using this feature as saving snapshots and later using them might create an overhead to the size and compute of your data.
If you are curious to learn more about it, read here.
That’s it.
I hope you enjoyed reading this short recap on open sources for January 2021.
If you are interested in learning more and getting updates, follow Adi Polak on Twitter..